In this article we’re going to create a project that scrapes and crawls a web site and stores its data in an in-memory data base. These are the technologies we’re going to use:
- Java 21
- Spring Boot 3.x.x
- Jsoup
- MapStruct
- H2 in-memory data base
The web site that we are going to crawl and scrape is the Books to Scrape, a fake book store created specifically for people to scrape it, so we don’t need to worry about being blocked while testing our application.
Creating and configuring the project
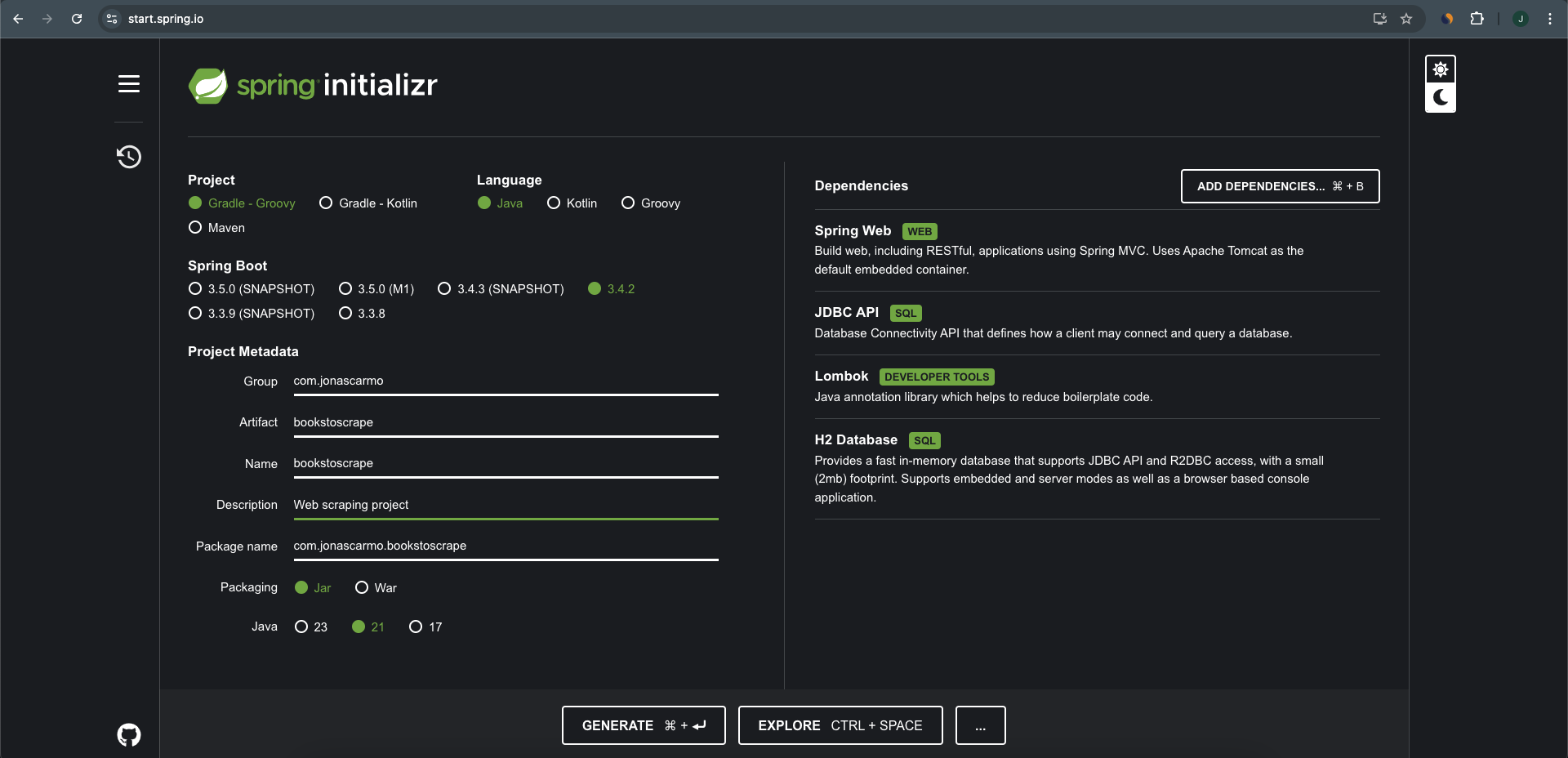
1 – Open Spring Initializr. We’re going to create a Java 21, Gradle project with the newest version of Spring Boot. As dependencies, we must include Spring Web, JDBC API, Lombok, and H2 Database.
2 – Open the project in IntelliJ IDEA (Community Edition or Ultimate). Next, open the build.gradle file. We’re going to add two more dependencies, Jsoup (HTML parser) and MapStruct (code generator for mappings between Java bean types).
implementation 'org.jsoup:jsoup:1.18.1'
implementation 'org.mapstruct:mapstruct:1.6.2'
annotationProcessor 'org.mapstruct:mapstruct-processor:1.6.2'Your build.gradle should look similar to this:
plugins {
id 'java'
id 'org.springframework.boot' version '3.4.2'
id 'io.spring.dependency-management' version '1.1.7'
}
group = 'com.jonascarmo'
version = '0.0.1-SNAPSHOT'
java {
toolchain {
languageVersion = JavaLanguageVersion.of(21)
}
}
configurations {
compileOnly {
extendsFrom annotationProcessor
}
}
repositories {
mavenCentral()
}
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-jdbc'
implementation 'org.springframework.boot:spring-boot-starter-web'
compileOnly 'org.projectlombok:lombok'
runtimeOnly 'com.h2database:h2'
annotationProcessor 'org.projectlombok:lombok'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
testRuntimeOnly 'org.junit.platform:junit-platform-launcher'
implementation 'org.jsoup:jsoup:1.18.1'
implementation 'org.mapstruct:mapstruct:1.6.2'
annotationProcessor 'org.mapstruct:mapstruct-processor:1.6.2'
}
tasks.named('test') {
useJUnitPlatform()
}
3 – Now, let’s add in application.properties file some configurations related to the database and the url we are going to scrape.
spring.application.name=bookstoscrape
spring.h2.console.enabled=true
spring.datasource.url=jdbc:h2:mem:bookstoscrapedb
spring.datasource.driver-class-name=org.h2.Driver
spring.datasource.username=sa
spring.datasource.password=sa
bookstoscrape.url=https://books.toscrape.com/Creating the web crawler and web scraper
Now let’s create the scraper. Our goal here is to scrape the information from all books from each category. To accomplish this we are going to create a class called BooksToScrapeInitializer that implements the CommandLineRunner interface. The class will be a managed bean, and the interface indicates that Spring Boot will automatically run the run() method after the application context is loaded. Below you can see this complete class, and next we’re going to break down each line of the code.
package com.jonascarmo.bookstoscrape;
import com.jonascarmo.bookstoscrape.dao.BooksToScrapeDao;
import com.jonascarmo.bookstoscrape.enums.StarRating;
import com.jonascarmo.bookstoscrape.model.Book;
import com.jonascarmo.bookstoscrape.model.Category;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.CommandLineRunner;
import org.springframework.context.annotation.Profile;
import org.springframework.stereotype.Component;
import java.io.IOException;
import java.math.BigDecimal;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.UUID;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
@Component
@Profile("!test")
public class BooksToScrapeInitializer implements CommandLineRunner {
private static final Logger log = LoggerFactory.getLogger(BooksToScrapeApplication.class);
private final BooksToScrapeDao booksToScrapeDao;
@Value("${bookstoscrape.url}")
private String booksToScrapeUrl;
public BooksToScrapeInitializer(BooksToScrapeDao booksToScrapeDao) {
this.booksToScrapeDao = booksToScrapeDao;
}
@Override
public void run(String... args) {
log.info("Parsing {}", booksToScrapeUrl);
Document doc = parseUrl(booksToScrapeUrl);
createTables();
log.info("Scrapping categories.");
List<Category> scrapedCategories = scrapeCategories(doc);
Object[] array = scrapedCategories.stream().map(Category::toString).toArray();
log.info(Arrays.toString(array));
log.info("Inserting categories into the database.");
booksToScrapeDao.insertCategories(scrapedCategories);
log.info("Scraping books catalogs.");
List<Book> books = scrapeBooksCatalogsFromAllCategories(scrapedCategories);
books = books.stream().map(this::scrapeBookInformation).toList();
log.info("Inserting books into the database.");
booksToScrapeDao.insertBooks(books);
log.info("Books inserted into the database.");
}
private Book scrapeBookInformation(Book book) {
log.info("Getting information about {} - {}", book.getCategory().name(), book.getName());
Document document = parseUrl(book.getUrl());
Element productDescriptionElement = document.getElementById("product_description");
String productDescription = productDescriptionElement != null ? productDescriptionElement.nextElementSibling().text() : null;
String starRatingClass = document.select("p.star-rating").getFirst().attr("class");
Elements tbody = document.select("table.table > tbody");
Elements tds = tbody.getFirst().getElementsByTag("td");
book.setDescription(productDescription);
book.setUpc(tds.getFirst().text());
book.setProductType(tds.get(1).text());
book.setPriceExcludingTax(new BigDecimal(sanitizePrice(tds.get(2).text())));
book.setPriceIncludingTax(new BigDecimal(sanitizePrice(tds.get(3).text())));
book.setTax(new BigDecimal(sanitizePrice(tds.get(4).text())));
book.setAvailability(tds.get(5).text());
book.setNumberOfReviews(Integer.valueOf(tds.get(6).text()));
book.setCurrency("£");
book.setStarRating(StarRating.getFromClassAttribute(starRatingClass));
return book;
}
private String sanitizePrice(String price) {
// Regular expression to extract the numeric value of a price
String regex = "\\d+(\\.\\d{1,2})?";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(price);
if (matcher.find()) {
return matcher.group();
}
return null;
}
private void createTables() {
log.info("Creating \"categories\" table.");
booksToScrapeDao.createCategoriesTable();
log.info("Creating \"books\" table.");
booksToScrapeDao.createBooksTable();
}
private List<Book> scrapeBooksCatalogsFromAllCategories(List<Category> scrapedCategories) {
List<Book> books = new ArrayList<>();
scrapedCategories.forEach(category -> {
log.info("Category: {}", category.name());
List<Book> scrapedBooks = scrapeBookCatalogFromCategory(category);
Object[] booksArray = scrapedBooks.stream().map(Book::getName).toArray();
log.info(Arrays.toString(booksArray));
books.addAll(scrapedBooks);
});
return books;
}
private Document parseUrl(String url) {
Document doc;
try {
doc = Jsoup.connect(url)
.userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36")
.get();
} catch (IOException e) {
throw new RuntimeException(e);
}
return doc;
}
private List<Category> scrapeCategories(Document doc) {
Elements categoryMenu;
List<Category> categories = null;
try {
categoryMenu = doc.select("ul.nav-list > li > ul > li");
categories = categoryMenu.stream().map(element -> {
Element link = element.select("a").getFirst();
return new Category(UUID.randomUUID(), link.text(), link.attr("abs:href"));
}).toList();
} catch (Exception e) {
System.out.println(e);
}
return categories;
}
private List<Book> scrapeBookCatalogFromCategory(Category category) {
return scrapeBookCatalogFromCategory(category, null);
}
private List<Book> scrapeBookCatalogFromCategory(Category category, String nextPageUrl) {
Document document;
if (nextPageUrl == null) {
document = parseUrl(category.url());
} else {
document = parseUrl(nextPageUrl);
}
Elements booksElements = document.select("div > ol.row > li");
List<Book> books = booksElements.stream().map(element -> {
Elements article = element.select("article");
Element bookLink = article.select("div > a").getFirst();
String url = bookLink.attr("abs:href");
String imgLink = bookLink.select("img").attr("abs:src");
String bookName = article.select("h3 > a").getFirst().attr("title");
return Book.builder()
.id(UUID.randomUUID())
.name(bookName)
.url(url)
.imgLink(imgLink)
.category(category)
.build();
}).toList();
List<Book> list = new ArrayList<>(books);
Elements nextPageElements = document.select("div > ul > li.next > a");
String nextPage = null;
if (!nextPageElements.isEmpty()) {
nextPage = nextPageElements.getFirst().attr("abs:href");
}
if (nextPage != null) {
list.addAll(scrapeBookCatalogFromCategory(category, nextPage));
}
return list;
}
}
1 – We annotate the class with @Component, indicating that this class should be a Spring bean; and @Profile(“!test”) tells that we don’t want to run the run() method during the unit tests.
2 – We inject the DAO object (more on that latter) through constructor injection, and get the url we want to scrape from the property bookstoscrape.url.
3 – On line 43 we override the run method from CommandLineRunner interface. Here, the first thing we do is to call the parseUrl() method, which uses Jsoup to parse the actual HTML page into Jsoup’s Document object. Next we create two tables in the data base: categories and books. From lines 50 to 54 we scrape the categories and inset them into the data base; and from lines 57 to 61 we scrape the book’s information and also store it into the data base.
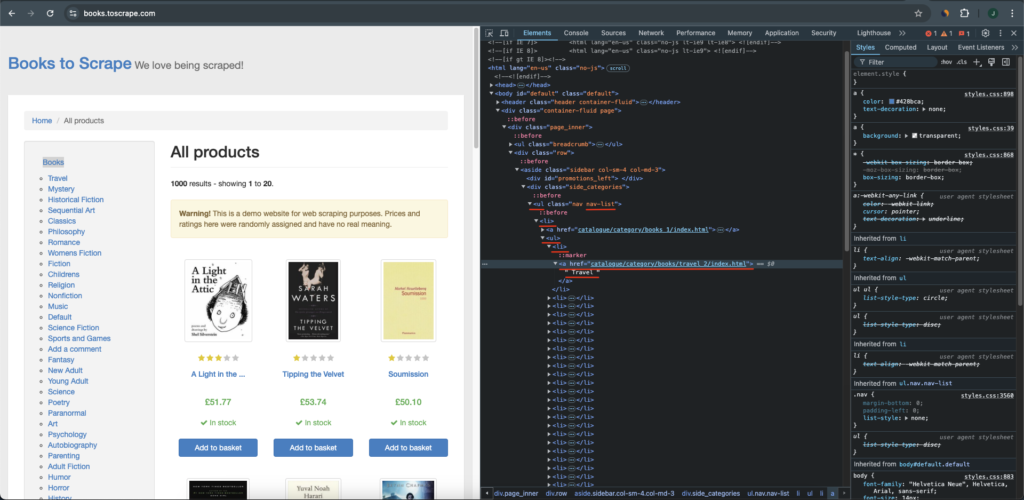
4 – The method scrapeCategories(Document doc), starting on line 128, uses Jsoup to get the link of each category on the side bar menu. Here we leverage Jsoup’s css selector to find the HTML elements we are looking for. To understand what exactly we are doing here, open the Developer Tools of your Browser to inspect the structure of the side bar menu:
5 – We pass the list of scraped categories to the method scrapeBooksCatalogsFromAllCategories(List<Category> scrapedCategories), on line 104. This method’s purpose is to get the link of each book from each category.
6 – The overloaded methods scrapeBookCatalogFromCategory(Category category) and scrapeBookCatalogFromCategory(Category category, String nextPageUrl) are called by the scrapeBooksCatalogsFromAllCategories(List<Category> scrapedCategories), mentioned above. They do a recursive call to actually get the link and other information from each book in each page of a category. The same way we did before, inspect the page to fully understand the Jsoup’s selector we’ve used.
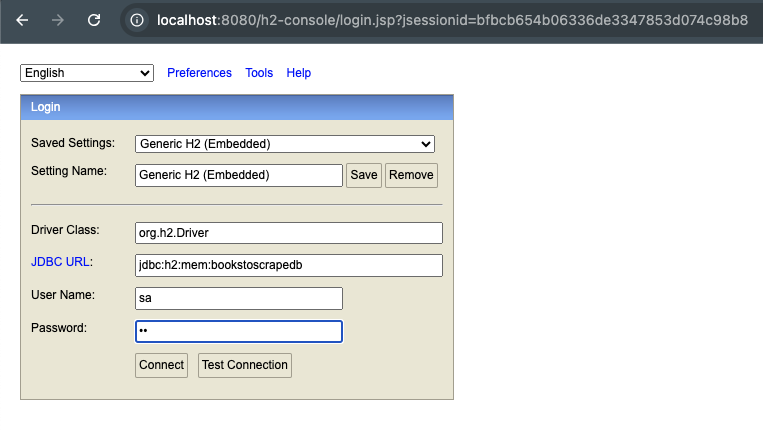
7 – Finally, we get the rest of the information from each book with the method scrapeBookInformation(Book book). At this point, we should have all are categories and books information stored in the data base H2. Let’s inspect those information. Open in your browser the link http://localhost:8080/h2-console. The User Name and Password are sa, according to our configuration in application.properties.
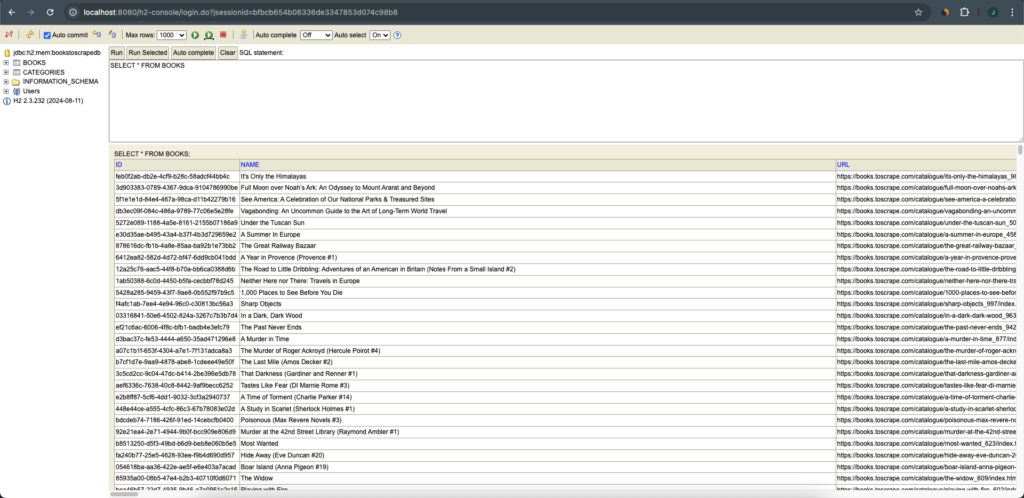
The DAO class
In this project we are using Spring’s JdbcTemplate to work with the in-memory H2 data base. This class supports any kind of JDBC operation, simplifies the use of JDBC and helps to avoid common errors. Below you can see the project’s DAO class, and next we’re going through each method of it.
package com.jonascarmo.bookstoscrape.dao;
import com.jonascarmo.bookstoscrape.model.Book;
import com.jonascarmo.bookstoscrape.model.Category;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.stereotype.Repository;
import javax.sql.DataSource;
import java.util.List;
@Repository
public class BooksToScrapeDao {
private JdbcTemplate jdbcTemplate;
@Autowired
public void setDataSource(DataSource dataSource) {
this.jdbcTemplate = new JdbcTemplate(dataSource);
}
public void createCategoriesTable() {
jdbcTemplate.execute("DROP TABLE categories IF EXISTS");
jdbcTemplate.execute("CREATE TABLE categories(" +
"id UUID PRIMARY KEY, name VARCHAR(50), url VARCHAR(255))");
}
public void createBooksTable() {
jdbcTemplate.execute("DROP TABLE books IF EXISTS");
jdbcTemplate.execute("CREATE TABLE books(" +
"id UUID PRIMARY KEY, name VARCHAR(255), url VARCHAR(255), imgLink VARCHAR(255)," +
"availability VARCHAR(50), description CLOB(10K), upc VARCHAR(20), productType VARCHAR(5)," +
"priceExcludingTax NUMERIC(5,2), priceIncludingTax NUMERIC(5,2), tax NUMERIC(5,2), numberOfReviews INT," +
"currency CHAR, starRating INT, category_id UUID," +
"FOREIGN KEY (category_id) REFERENCES categories(id))");
}
public void insertCategories(List<Category> scrapedCategories) {
List<Object[]> elements = scrapedCategories
.stream()
.map(category -> new Object[]{category.id(), category.name(), category.url()}).toList();
jdbcTemplate.batchUpdate("INSERT INTO categories(id, name, url) values (?, ?, ?)", elements);
}
public void insertBooks(List<Book> books) {
List<Object[]> elements = books
.stream()
.map(book -> new Object[]{book.getId(), book.getName(), book.getUrl(), book.getImgLink(),
book.getAvailability(), book.getDescription(), book.getUpc(), book.getProductType(),
book.getPriceExcludingTax(), book.getPriceIncludingTax(), book.getTax(),
book.getNumberOfReviews(), book.getCurrency(), book.getStarRating().getNumberOfStars(),
book.getCategory().id()}).toList();
jdbcTemplate.batchUpdate("INSERT INTO books(id, name, url, imgLink, " +
"availability, description, upc, productType, priceExcludingTax, " +
"priceIncludingTax, tax, numberOfReviews, currency, starRating, category_id) " +
"values (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)", elements);
}
}
1 – We annotate the class with @Repository, indicating that this class should be a Spring bean. Then we inject a DataSource object through setter injection on line 18; with that object we instantiate the JdbcTemplate.
2 – On lines 22 and 28 we create the Categories and the Books tables, respectively. Next, on lines 38 and 45, we use the batchUpdate(String sql, List<Object[]> batchArgs) method to inset all books and categories in the database at once. To learn more about JdbcTemplate, see Spring’s guide on the subject.
Conclusion
In this tutorial we learned how to create simple Web Scraper and Web Crawler with Java, Spring Boot and Jsoup. We also learned a little bit about the H2 relational data base and how to work with it inside Spring Boot. To clone the entire project, please open its GitHub Page.
To learn more about Spring and Spring Boot, follow this link; to read our Java articles, please click here.

